Хочу делиться
После того, как ты обучил модель, которая показывает хорошие результаты, всегда хочется поделиться этой радостью с окружающими, хочется сказать: "Смотри, у меня есть модель, которая может сказать, кто на картинке: кошка или собака. Хочешь попробовать? Вот загрузи фотографию своей Мурки".
Но делать клиент-серверное приложение с крутым дизайном очень лень, на это ты потратишь больше времени, чем на саму модель. Что же делать? Не отправлять же всем свой код, в самом деле!
Выход есть! Нам поможет... Подождите, давайте все сделаем попорядку.
В этой статье у меня нет цели рассказать вам в подробностях, как обучать модель, цель этой статьи - показать, как быстро получить из модели готовое приложение. Поэтому на этом разделе не буду долго задерживаться. Итак, обучение модели. Поехали!
Сначала импортируем библиотеку. Раскомментируйте первую ячейку, если у вас еще не установлен fastai или установлена старая версия.
#!pip uninstall fastai
#!pip install fastai
from fastai.vision.all import *
from fastai.vision.widgets import *
Теперь возьмем уже существующий датасет с кошками и собаками, который нам предоставляет эта библиотека, и загрузим его на свою машину:
path = untar_data(URLs.PETS)
path
Метод untar_data, как я уже сказала, скачивает датасет на сервер, где производятся вычисления: если вы считаете на локальном компьютере, то скачивает на ваш локальный компьютер, если вы считаете где-нибудь на Colab или Gradient, то на ту виртуальную машину и загружает. Затем этот метод распаковывает архив, если данные заархивированы, и возвращает путь, где лежат конечные данные.
Давайте посмотрим, что лежит внутри загруженной папки:
Path.BASE_PATH = path
path.ls()
Вы видели, какой у нас длинный путь, в котором лежит датасет. Чтобы не отображать его каждый раз, в первой строчке мы сделали адрес этой папки базовым. Таким образом, когда мы с помощью метода ls() отображаем содержимое папки, мы видим пути относительно этого базового адреса.
Итак, у нас внутри две папки: annotations и images. Папка annotations нас не интересует - там лежат данные для определения конкретного места на картинке, где изображены животные. Нас интересует папка images. Давайте заглянем в нее:
path = path/'images'
path.ls()
Все верно. В папке images лежат 7393 изображения с кошками и собаками различных пород. Если мы внимательно посмотрим на названия картинок, то увидим, что это названия пород. А если посмотрим еще более внимательно, то увидим, что породы кошек написаны с большой буквы, а собак - с маленькой. Ну или можно было получить эту информацию с сайта, с которого мы скачали наши данные:)
Породы нам пока не нужны, а вот принцип отделения кошек от собак полезен. Оформим его в виде отдельного метода:
def cat_or_dog(x):
return 'Cat' if x[0].isupper() else 'Dog'
Загрузим наши данные таким образом, чтобы они представляли собой структуру, удобную для дальнейшей обработки. В этом нам поможет класс ImageDataLoaders:
dls = ImageDataLoaders.from_name_func(path,
get_image_files(path),
valid_pct = 0.2,
seed = 42,
label_func = cat_or_dog,
item_tfms = Resize(224))
Если вы читали мой пост, в котором я рассказывала об основных понятиях нейронных сетей, то вы быстро поймете, что здесь произошло, а если нет, то предлагаю вам быстренько с ним ознакомиться.
Итак, разбираем построчно.
dls - переменная, в которой будет храниться структура из наших изображений.
ImageDataLoaders - собственно класс, который эту структуру представляет. Эта структура удобна тем, что в ней хранится информация, откуда брать таргеты (labels) для изображений, откуда брать сами изображения, как их делить на тренировочные и валидационные выборки и многое другое.
Собственно, функция from_name_func и показывает, что при создании загрузчика файлов(этой самой структуры), таргеты для каждого изображения будем брать из его имени.
Функции передаем:
- путь, откуда брать файлы;
- функцию, показывающую, каким образом брать эти файлы (get_image_files - брать изображения рекурсивно из каждой подпапки);
- valid_pct - какую часть от всех изображений выделить под валидационную выборку;
- seed - ядро для рандома, чтобы в валидацонную выборку попали случайные изображения, но чтобы на каждой эпохе эта выборка была одной и той же;
- label_func - задаем функцию, каким образом получить таргет. Помните, мы определили метод, определяющей по первой букве названия файла кошка перед нами или собака? Его мы и передадим.
- item_tfms - какие преобразования проделать с каждым изображением. В данном случае просто преобразуем все изображения к одному размеру (224*224), чтобы можно было работать с ними на ГПУ.
Как видите, ничего сложного. Делаем все необходимое, что написано в том посте, который я только что упомянула, буквально в одной строчке.
Идем дальше. Данные готовы, что делаем с моделью? Возьмем предобученную модель и дообучаем ее на своих данных. Для нашей не самой сложной модели возьмем хорошую сеть из 34-ти слоев: ResNet34.
learner = cnn_learner(dls, resnet34, metrics=error_rate)
Метод cnn_learner строит сверточную нейронную сеть из наших данных и из предобученной модели. Мы можем передать ему большое число параметров, например, loss function, оптимизирующую функцию, шаг (learning rate) и так далее. Но сейчас мы передали ему только метрику, которую хотели бы использовать - error_rate (отношение количества ошибочных предсказаний к общему числу предсказаний).
Кстати, если вы хотите подробнее узнать о той или иной функции, то можете использовать метод doc() или поставить ? или ?? перед именем функции. Попробуйте, это удобно!
doc(cnn_learner)
?cnn_learner
??cnn_learner
Итак, нам остался последний шаг - собственно, само обучение. Вернее, дообучение модели на наших данных:
learner.fine_tune(4)
Дообучение модели иногда называют файнтьюнингом от английского термина fine-tune. Поэтому метод дообучения так и называется. В качестве параметра мы передаем число эпох. Например, 4.
4 эпохи дали нам очень неплохой результат. Я удовольствуюсь им, а вы, если хотите, можете посмотреть, как будет изменяться точность с дальнейшим обучением.
Можем сохранить нашу модель, чтобы в следующий раз, когда она нам понадобится, нам не пришлось заново ее обучать. Есть 2 способа сохранить модель:
- Можно сохранить только параметры, тогда при следующем использовании мы будем брать брать нужную нам архитектуру модели (в данном случае, resnet34) и передавать ей сохраненные параметры.
- Можно сохранить сразу все: и параметры, и архитектуру, и при следующем использовании нам просто надо будет просто взять модель из сохраненного файла.
Как вы догадываетесь, в первом случае сохраненный файл весит гораздо меньше, но требуется чуть больше хлопот. Не будем пока заморачиваться и сохраним всю модель целиком, как в пункте 2:
learner.export(os.path.abspath('./export.pkl'))
Метод export сохраняет модель в файл с разрешением .pkl в текущую папку.
По умолчанию имя файла будет "export.pkl", но вы можете передать в метод другое имя или абсолютный путь.
Проверим, что все сохранилось:
path = Path()
path.ls(file_exts=".pkl")
Но если в Gradient ваша модель сохранится за вами, и вы снова увидите ее, если зайдете на следующий день, то с Colab-ом так, к сожалению, не прокатит. Зато с Colab удобно сохранять модель на гугл-диск. Для этого надо зайти на свой диск и выбрать место, куда сохранить:
from google.colab import drive
drive.mount('/content/gdrive')
learner.export('/content/gdrive/My Drive/export.pkl')
Можете проверить, на вашем Google диске должен появиться файл с расширением .pkl.
Теперь мы хотим загрузить полученную нами модель для дальнейшего использования. (Конечно, загружать модель в этом же блокноте нам сейчас особого смысла нет, но давайте представим, что мы создали новый jupyter-notebook и теперь работаем в нем. Кстати, вы можете именно так и поступить!)
Чтобы загрузить модель, используем метод load_learner.
learner_s = load_learner(path/'export.pkl')
Модель загружена. Давайте посмотрим, помнит ли она, на какие два класса она должна делить изображения. Обратимся к загрузчику классов и посмотрим, какие таргеты у него есть:
learner_s.dls.vocab
Отлично. Чтобы сделать предсказание, будем пользоваться методом predict. Но для начала давайте получим самый простой интерфейс для загрузки картинок и "скармливания" их нашей модели. Начинается самая интересная часть, ради которой и была написана эта статья.
Для людей, не сильно любящих заниматься разработкой графического пользовательского интерфейса(GUI), существуют IPython widgets. Это GUI-компоненты, помогающие быстро и без особых трудностей создать простой пользовательский интерфейс прямо в jupyter notebook-е.
Давайте посмотрим, что он умеет.
Создадим кнопку для загрузки изображения с локального компьютера. Самое прекрасное, что такая кнопка уже есть в виджетах и нам не придется писать для нее функционал самим.
btn_upload = widgets.FileUpload()
btn_upload
Попробуйте загрузить какое-нибудь изображение. Чтобы его отобразить, выделим место, в котором будут отображаться загруженные картинки:
placeholder = widgets.Output()
placeholder
Видите, мы его создали, но пока там пусто. Давайте отобразим там ваше загруженное изображение:
img = PILImage.create(btn_upload.data[-1])
with placeholder: display(img.to_thumb(250,250))
Чтобы снова очистить это место, используем метод clear_output():
placeholder.clear_output()
А теперь посмотрим, что скажет нам наша модель:
learner_s.predict(img)
Здорово! Нам выводится 3 значения:
- Таргет (класс, к которому наша модель относит наше изображение)
- Порядковый номер этого класса
- Вероятности, с каким это изображение относится к каждому из классов
Давайте создадим специальное место, где будем отображать предсказание:
pred, ndx, probs = learner_s.predict(img)
lbl_pred = widgets.Label()
lbl_pred.value = f'Предсказание: {pred}; Вероятность: {probs[ndx]:.04f}'
lbl_pred
Хочется, чтобы картинка и предсказания отображались сразу после того, как мы загрузим изображение. Для этого объединим все действия выше в один метод и скажем, чтобы его выполняла загрузочная кнопка:
def on_click(change):
img = PILImage.create(btn_upload.data[-1])
placeholder.clear_output()
with placeholder: display(img.to_thumb(250,250))
pred, ndx, probs = learner_s.predict(img)
lbl_pred.value = f'Предсказание: {pred}; Вероятность: {probs[ndx]:.04f}'
btn_upload.observe(on_click)
Теперь давайте соберем все элементы вместе. Расположим их друг над другом в элементе VBox:
VBox([widgets.Label('Загрузите картинку с кошкой или собакой!'), btn_upload, placeholder, lbl_pred])
Здорово, правда? Но это не все. Все-таки, приложение в блокноте не всегда нас полностью удовлетворяет. Нам не хочется показывать другим людям блокнот с кодом, нам хочется показать только конечный разультат. И тут нам на помощь приходит Voilà. Voilà - система, которую можно использовать как отдельное приложение, а можно как расширение jupyter notebook-а, что мы и будем делать. Voilà создает веб приложение из jupyter notebook-а: он отображает выводы из ячеек, текстовые ячейки и IPython widgets и при этом скрывает ячейки с кодом.
Давайте вынесем в отдельный блокнот только тот код, который нам необходим для создания веб-приложения (то есть загрузку модели и создание приложения с помощью виджетов). Можете добавить какой-нибудь текст, оформленный с помощью Markdown.
Чтобы установить voila, скопируйте следующую ячейку в блокнот и раскомментируйте строки. Первая строка устанавливает Voilà, а вторая устанавливает связь между нею и блокнотом. Или можно использовать командную строку.
# !pip install voila
# !jupyter serverextension enable voila --sys-prefix
После установки, если она прошла успешно, у вас должен появиться значок Voilà. Примерно вот такой:
![]()
Можно нажать на него и увидеть результат. А можно в URL вашего текущего блокнота заменить "notebook" на "voila/render", результат будет тот же.
Помните, в моем посте о приборах и материалах я говорила, что в Colab-е возникают проблемы с использованием voila? Если вы работаете на Colabe и у вас возникли проблемы, попробуйте проделать тоже самое, например, в Gradient-е или даже у себя на локальном компьютере, ведь модель уже обучена, и мы можем обойтись и без мощного ГПУ. Только не забудьте подгрузить файл с вашей моделью.
Все это, конечно, хорошо, но хочется, чтобы мы могли показывать свои достижения не только со своего компьютера. Именно для удовлетворения этой потребности и существует Binder.
Binder - ПО, которое из Git-репозитория делает веб-приложение.
Как это работает?
-
Создаем репозиторий в своем GitHub-аккаунте,куда загружаем:
- jupyter notebook, в котором и содержится наше приложение
- обученную модель
-
файл requirements.txt, в котором указаны требования к библиотекам и зависимостям, необходимым для работы нашего приложения. В нашем конкретном случае в файле содержатся 5 строк:
voila
fastai>=2
pillow<7
packaging
ipywidgets==7.5.1
- На сайте https://mybinder.org/ указываем ссылку на репозиторий в строке "GitHub repository name or URL", в строке "URL to open" вводим /voila/render/имя_вашего_jupyter_notebookа.ipynb и заменяем File на URL в выпадающем списке, как показано на картинке.
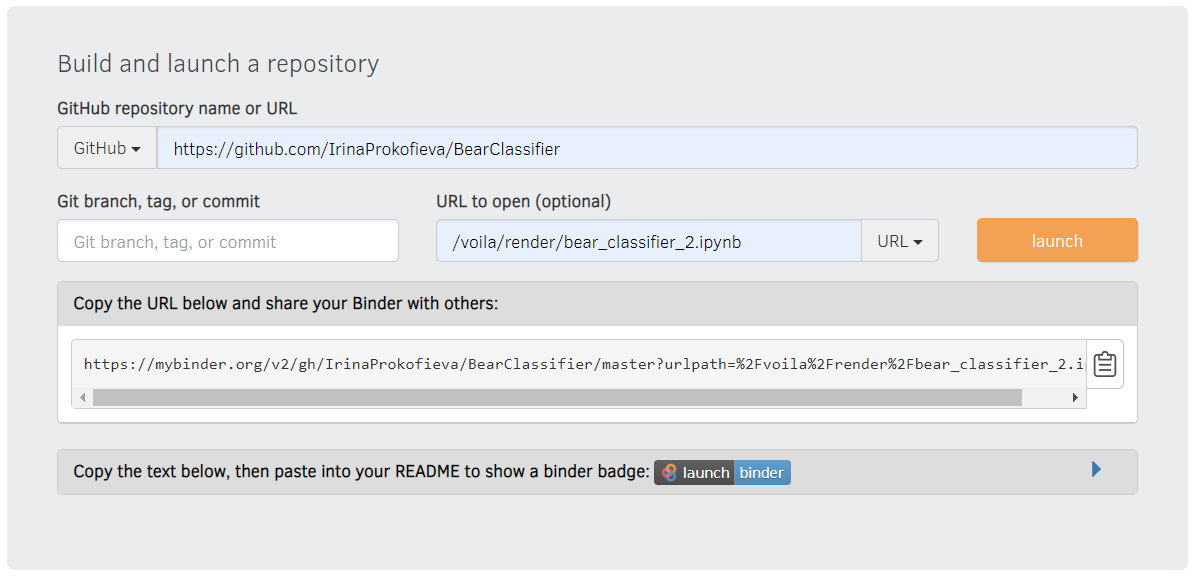
- Нажимаем кнопку launch.
- Binder находит файл с зависимостями (requirements.txt) и, опираясь на него, начинает строить Docker образ нашего репозитория. Если для этого репозитория уже был построен образ, то он не будет перестраивать его заново. Если были произведены какие-то изменения в репозитории, то образ тоже обновится.
- Когда образ построен, запустится страничка с вашим приложением. Вы можете использовать ссылку на него, чтобы поделиться своими успехами с друзьями.
Ура! Приложение готово, и нам не пришлось долго мучиться с его оформлением и размещением!
Если у вас возникли проблемы, можете посмотреть для примера на мой репозиторий https://github.com/IrinaProkofieva/BearClassifier. Если у вас возникли вопросы, пишите в комментариях)
До новых встреч!